🔍 亚洲编码区域划分 🔍
亚洲编码区域的划分主要基于Unicode标准,分为一码区、二码区和三码区。这种划分方式对于软件开发和字符处理具有重要意义,尤其是在多语言系统的设计和实现过程中。
💡 一码区特点与应用 💡
一码区覆盖了最基础的汉字字符,包含了GB2312-80标准中的6763个汉字和682个其他符号。这些字符在计算机系统中使用频率最高,占用存储空间较小,编码效率高。对于开发者来说,一码区字符的处理速度快,系统资源消耗少,适合开发轻量级应用程序。
🔧 二码区技术特征 🔧
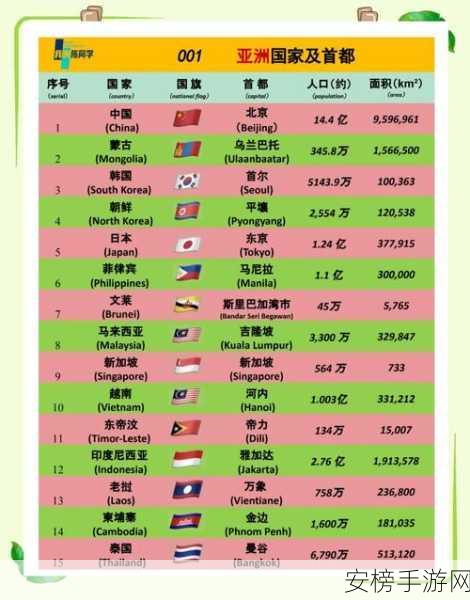
二码区扩充了一码区的字符集,增加了GBK标准中的繁体字和生僻字,共计20902个汉字。二码区的编码范围更广,但字符处理复杂度相应提高。程序开发时需要考虑更多的字符编码转换和兼容性问题,特别是在跨平台应用中。
⚡ 三码区编码实现 ⚡
三码区是GB18030标准的扩展部分,包含了Unicode中的所有字符,支持少数民族文字、特殊符号等。三码区的实现需要更复杂的编码算法和更大的存储空间,对系统性能要求较高。开发人员在处理三码区字符时,需要特别注意内存管理和性能优化。
📱 编程实践中的区别 📱
编程实践中,不同码区的选择直接影响着程序的性能和兼容性。一码区适合开发面向普通用户的常用应用;二码区适用于需要支持繁体字的系统;三码区则用于开发全语言支持的专业软件。开发者需要根据项目需求,合理选择编码方案,平衡系统性能和功能完整性。
❓ 常见问题解答 ❓
Q1:为什么一码区的处理速度最快? A1:一码区使用固定双字节编码,字符映射简单,查找和转换效率高,且覆盖最常用字符。
Q2:在跨平台开发中如何处理不同码区的兼容性? A2:建议使用Unicode编码作为内部编码,在输入输出时进行相应的编码转换,确保数据的正确传输和显示。
Q3:开发多语言系统时应该选择哪个码区? A3:建议采用三码区(GB18030)标准,虽然会增加系统开销,但能确保对所有可能出现的字符的支持。