🌐 日韩乱码的技术解析与应对策略
日韩乱码问题一直是IT技术人员和用户面临的棘手挑战。这种编码错误不仅影响阅读体验,还可能导致严重的信息传递障碍。通过深入剖析乱码产生的根本原因,我们可以更好地理解和解决这一技术难题。
🔍 乱码的技术本质
乱码本质上是字符编码转换过程中的不匹配问题。常见的编码如UTF-8、Shift-JIS、GBK等在处理多语言文本时经常出现冲突。当系统无法正确识别字符集时,就会产生难以辨认的乱码符号。

💻 编码转换的关键技术
解决乱码问题需要精确的字符编码转换技术。开发者可以通过多种编程语言提供的编码转换函数,如Python的decode()和encode()方法,或者Java中的CharsetEncoder和CharsetDecoder类,实现精准的编码转换。
🛠️ 实用解决方案
针对日韩乱码,技术人员可以采用以下具体策略: 1. 统一使用UTF-8编码作为标准字符集 2. 在数据传输前进行严格的编码检测 3. 使用专业的编码转换工具库 4. 在web应用中设置正确的meta charset声明
🚀 前端处理技巧
前端开发者可以通过JavaScript的encodeURIComponent()和decodeURIComponent()函数有效处理编码问题。对于Ajax请求,建议明确指定数据的字符编码类型,避免出现意外的乱码情况。
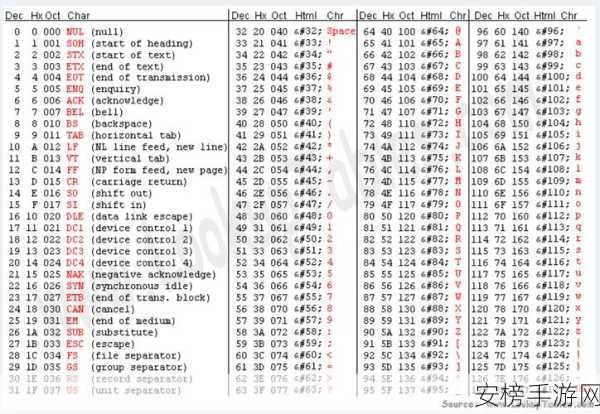
🔬 深入编码诊断
专业的乱码诊断需要使用十六进制编辑器和字符集转换工具。开发者可以通过分析字节级别的编码差异,准确定位乱码产生的具体环节,从而制定targeted解决方案。