本文深入探讨Few-shot Learning的不稳定性,分析影响其精度的关键因素,并分享最新动态。
近年来,随着人工智能技术的飞速发展,机器学习领域中的Few-shot Learning(小样本学习)逐渐崭露头角,这种技术旨在通过极少的训练样本实现高效的模型学习,为众多应用场景带来了革命性的改变,尽管Few-shot Learning潜力巨大,但其在实际应用中的稳定性却备受关注,不少研究者发现,Few-shot Learning模型的性能往往波动较大,难以保持一致的高精度,究竟有哪些因素在影响着Few-shot Learning的稳定性呢?本文将对此进行深入探讨。
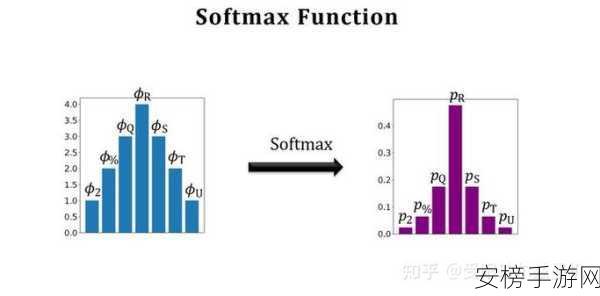
中心句:数据质量与多样性是影响Few-shot Learning稳定性的关键因素之一。
在Few-shot Learning的框架下,训练样本的数量极为有限,数据的质量与多样性就显得尤为重要,如果训练数据中存在噪声或标签错误,将直接影响模型的训练效果,导致性能下降,数据的多样性不足也会使模型难以学习到泛化能力强的特征,从而在面对新样本时表现不佳,为了提升Few-shot Learning的稳定性,研究者们需要更加注重数据集的构建与预处理,确保数据的准确性和多样性。

中心句:模型架构与训练策略对Few-shot Learning稳定性同样具有重要影响。
除了数据因素外,模型架构的选择与训练策略的制定也是决定Few-shot Learning稳定性的关键,不同的模型架构在处理小样本数据时具有不同的优势与劣势,一些模型可能更适合捕捉数据的局部特征,而另一些则更擅长学习全局结构,在选择模型架构时,需要根据具体应用场景和数据特点进行权衡,训练策略的优化也是提升稳定性的重要手段,通过引入正则化项、使用迁移学习等方法,可以有效缓解小样本学习中的过拟合问题,提高模型的泛化能力。
中心句:算法创新与改进为Few-shot Learning稳定性提供了新的解决方案。
面对Few-shot Learning稳定性的挑战,研究者们不断探索新的算法与改进方法,元学习(Meta-Learning)和自监督学习(Self-Supervised Learning)等先进技术为Few-shot Learning提供了新的思路,元学习通过从多个任务中学习如何学习,使模型能够更好地适应小样本场景,而自监督学习则通过利用数据本身的特性进行预训练,提升模型对未标注数据的理解能力,这些算法的创新与改进为Few-shot Learning的稳定性提供了新的解决方案,推动了该领域的持续发展。
中心句:最新动态显示,研究者们正致力于开发更稳定、高效的Few-shot Learning方法。
关于Few-shot Learning稳定性的研究取得了不少新进展,一些研究者提出了基于图神经网络的Few-shot Learning方法,通过构建样本之间的关系图来增强模型的泛化能力,另一些研究者则关注于将深度学习与传统机器学习算法相结合,以充分利用两者的优势,还有一些研究致力于开发适用于特定应用场景的Few-shot Learning解决方案,如医疗影像分析、自然语言处理等,这些最新动态表明,研究者们正不断努力提升Few-shot Learning的稳定性与实用性,为人工智能技术的广泛应用奠定坚实基础。
Few-shot Learning的稳定性问题是一个复杂而重要的课题,数据质量与多样性、模型架构与训练策略以及算法创新与改进等因素共同影响着其精度与稳定性,随着研究的不断深入和技术的不断进步,相信未来我们将看到更多稳定、高效的Few-shot Learning方法涌现出来,为人工智能技术的发展注入新的活力。